Data Preprocessing Menggunakan Library Python Scikit-learn
Preprocessing data adalah tahap penting dalam pembelajaran mesin, karena data masukan yang baik dan tepat (harusnya) akan membuat estimator mampu menghasilkan keluaran yang baik pula.
Tulisan ini menjelaskan secara singkat beberapa langkah yang sering dijumpai dalam tahap data preprocessing:
- Impor dataset dari file,
- Menangani nilai data yang kosong/hilang menggunakan imputer,
- Mengkodekan data kategori menggunakan one hot encoding,
- Membagi dataset menjadi training set, validation set, dan test set,
- Feature scaling berdasarkan mean dan deviasi standar, range nilai (min-max), atau range inter kuartil.
Semua contoh di bawah menggunakan paket Anaconda 3 (2019.3), IDE Spyder 3.3.3, Python 3.7.
Impor library
Ada dua library populer yang digunakan dalam tulisan ini selain Scikit, yaitu Numpy dan Pandas.
# impor library
import numpy as np
import pandas as pd
Dataset contoh yang digunakan dapat diunduh di sini atau dihasilkan langsung dari kode di bawah. Sebaiknya, letakkan file csv di direktori yang sama dengan file python sumber.
data = {
'Province': ['Banten', 'DKI Jakarta','Jawa Barat','Banten','Jawa Barat','DKI Jakarta','Banten','Banten','Jawa Barat','DKI Jakarta','Banten','Banten','Jawa Barat','DKI Jakarta','DKI Jakarta'],
'Age': [24,np.nan,60,34,58,np.nan,21,44,40,51,32,30,30,19,25],
'Wage': [5000000,3400000,7350000,3500000,np.nan,8000000,5500000,10000000,9000000,10500000,np.nan,6400000,np.nan,2200000,4500000],
'Life insured': ['Yes','No','No','No','Yes','No','No','Yes','Yes','Yes','No','No','No','Yes','Yes'],
}
dataset = pd.DataFrame(data)
Dataset dalam wujud tabel:
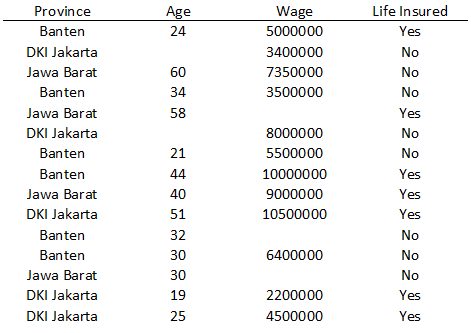
Terdapat 15 observasi. Anggaplah setiap observasi merupakan data seorang karyawan, yang terdiri atas provinsi asal, usia (tahun), gaji (rupiah), dan apakah mereka memiliki asuransi jiwa.
Impor dataset dari file csv
Jalankan kode di bawah hanya jika Anda memutuskan mengunduh file csv dataset.
# impor dataset
dataset = pd.read_csv(
'contoh_dataset.csv',
delimiter=';',
header='infer',
index_col=False
)
Ada beberapa parameter metode read_csv():
- Nama file (dalam hal ini
contoh_dataset.csv), delimiter: meskipun format file adalah csv (comma separated values), delimiter data belum tentu karakter koma (dalam hal ini;),header: indeks baris yang digunakan sebagai nama kolom, dalam hal ini ditentukan secara otomatis oleh library ('infer'),index_col: kolom yang digunakan sebagai label baris dan indexing. Tidak diperlukan untuk kasus ini (False).
Untuk melihat sekilas dataframe yang telah diimpor, jalankan perintah dataset.head(). Terlihat ada beberapa nilai yang kosong (NaN).
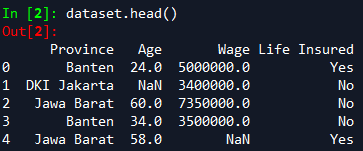
Data kemudian dibagi menjadi dua jenis: data independen/prediktor (X) dan data dependen/target (y). Pembagian data ini menggunakan pandas.DataFrame.iloc seperti di bawah. Karena dataset adalah matriks M*N, kita menggunakan slicing dengan format [baris, kolom].
Contoh format slicing:
[:, :-1]: pilih semua baris dalam dataset, serta semua kolom kecuali kolom terakhir (ingat negative indexing pada Python).[:, 0:3]: idem, tanpa negative indexing (ada empat kolom pada dataset, kita memilih tiga kolom: indeks 0, 1, dan 2).[:, -1]: pilih semua baris, kolom terakhir.
Untuk dataset contoh:
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
Atribut values akan mengembalikan numpy array. Tanpa atribut ini, iloc akan mengembalikan obyek DataFrame. Karena province, age, dan wage adalah tipe data yang berbeda, tipe data numpy array yang dikembalikan adalah campuran/object (dtype=object).
Menangani nilai kosong (NaN)
Seperti terlihat pada gambar preview dataset sebelumnya, ada beberapa observasi yang nilainya tidak lengkap (missing value). Ada dua pilihan: hapus observasi itu, atau substitusi nilai dengan mean/rata-rata kolom itu. Tentu saja, harapannya data yang Anda gunakan sebagai data masukan sudah lengkap dan baik sejak awalnya, sehingga cara ini tidak perlu dilakukan.
Pada contoh ini, nilai yang kosong itu akan digantikan dengan mean kolom. Kelas yang digunakan adalah SimpleImputer().
# menangani nilai kosong
from sklearn.impute import SimpleImputer
# ganti NaN dengan mean kolom itu
imputer = SimpleImputer(
missing_values=np.nan,
strategy='mean'
)
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
Ketika membuat obyek dari kelas SimpleImputer, terdapat beberapa parameter yang harus diatur:
missing_values: nilai data yang digunakan sebagai penanda bahwa nilai aslinya tidak ada (missing); dalam hal ini NaN (np.nan)strategy: dalam hal ini rata-rata kolom ('mean'), bisa juga menggunakan'median','most_frequent'(modus), atau'constant'
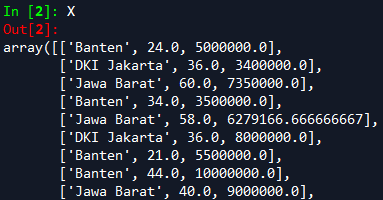
Selanjutnya obyek imputer harus di fit berdasarkan kolom yang bersangkutan menggunakan metode fit(), dalam hal ini X kolom indeks 1 (age) dan 2 (wage). Nilai kosong pada kedua kolom itu akan diubah menggunakan metode transform().
Sekarang X memiliki data yang lengkap, terlihat pada gambar di bawah.
Mengkodekan data kategori
Pada matriks X yang telah kita buat, terdapat kolom yang nilai datanya bertipe string, yaitu Province. Pada banyak kasus dan algoritma machine learning, data seperti ini harus diubah menjadi numerik (entah itu int atau float) agar dapat digunakan dengan baik.
Kita dapat saja mengkodekan nama-nama provinsi seperti Banten, DKI Jakarta, dan lain-lain menjadi 0, 1, dan seterusnya. Masalahnya, estimator bisa saja menganggap kode provinsi memiliki relasi order (misalnya karena 1 > 0), padahal kita tahu itu hanya sebatas kode angka.
Solusinya kita harus menggunakan variabel dummy menggunakan OneHotEncoder dan ColumnTransformer.
# kodekan data kategori
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# kodekan nama provinsi (kolom ke-0)
# kode hanya sebatas penanda
encoder_X = ColumnTransformer(
[('province_encoder', OneHotEncoder(), [0])],
remainder='passthrough'
)
X = encoder_X.fit_transform(X).astype(float) # mengembalikan ke dalam tipe 'float64'
Ketika membuat obyek encoder_X dari kelas ColumnTransformer, ada beberapa parameter yang harus diatur:
- list Python berisi tuple berisi: string yang digunakan untuk mengenali transformer (misal
'province_encoder'), nama transformer (OneHotEncoder()), dan list kolom (Province memiliki index 0) remainder: apakah kolom sisanya akan disertakan pada output ('passthrough') atau tidak ikut ('drop').
Sekarang, kolom Province telah selesai dikodekan. Terlihat pada gambar di bawah bahwa karyawan pertama berasal dari Banten. Per observasi, nilai 1 adalah unik. Terlihat kolom 3 dan 4 adalah usia dan gaji.
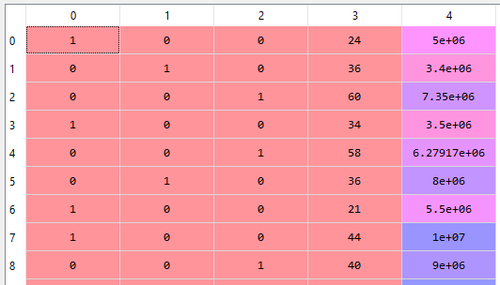
Jalankan perintah di bawah untuk mengetahui urutan variabel dummy pada matriks X.
print(encoder_X.named_transformers_['country_encoder'].categories_)
Bagaimana dengan variabel target (y) ? Untuk kasus ini, kita hanya akan mengubahnya menjadi numerik (0, 1, dan seterusnya) dengan LabelEncoder:
# y adalah dependent, cukup kodekan ke angka
from sklearn.preprocessing import LabelEncoder
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
Pada contoh di atas, kita menggunakan fit_transform(), jalan pintas dari fit() dan transform(). Sekarang y akan menjadi seperti terlihat pada gambar di bawah. Terlihat bahwa 1 dan 0 telah menggantikan Yes dan No.
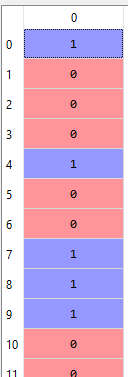
Membagi dataset ke dalam training set dan test set
Model machine learning umumnya membutuhkan dua set data untuk "belajar" dan menghasilkan estimasi: training set dan test set. Biasanya training set ini memiliki proporsi lebih besar dibandingkan test set, misal 80%.
Untuk dataset yang digunakan dalam tulisan ini:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
Untuk parameter:
test_size: proporsi test set, dalam hal ini 0.2.train_size: proporsi train size. Jika tidak di set, maka akan menyesuaikan dengan test size (dalam kasus ini 0.8). Berlaku kebalikannya.random_state: konstan ini akan membuat hasil splitting tetap sama antar runtime atau antar mesin. Nilai bebas.
Karena kita hanya memiliki 15 observasi, rasionya menjadi 12:3.
Gambar di bawah menunjukkan training set untuk X dan y.
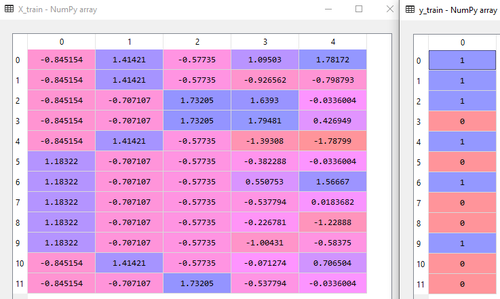
Bagaimana dengan validation set? Untuk mendapatkan tiga set (train, validate, test), cukup jalankan train_test_split() dua kali. Yang pertama untuk mendapatkan test set, yang kedua kali untuk mendapatkan validation set dari training set. Validation set biasanya digunakan untuk mendapatkan hyperparameter yang tidak didapatkan dari mempelajari training set.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# kemudian:
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=1)
Feature Scaling
Kita perlu menskalakan kolom-kolom yang dibutuhkan. Perbedaan skala dapat menyebabkan kendala dengan estimator. Ingat euclidean distance.
(Pada contoh ini, hanya X yang diskalakan. Untuk kasus tertentu, variabel independen dan dependen harus diskala.)
Ada tiga scaler di library scikit-learn yang sering digunakan: StandardScaler, MinMaxScaler, dan RobustScaler.
StandardScaler menghilangkan mean (terpusat pada 0) dan menskalakan ke variansi (deviasi standar = 1), dengan asumsi data terdistribusi normal (gauss) untuk semua fitur. Formulanya
$$z = (x - u)/s$$,
dengan $$u$$ adalah mean sampel dan $$s$$ adalah deviasi standar (DS) sampel.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
# variabel dummy kode provinsi juga diskalakan
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Sebenarnya ada dua parameter boolean yang bisa diatur untuk StandardScaler(), yaitu with_mean dan with_std. Umumnya biarkan saja ke default, yaitu True.
Terlihat pada potongan kode di atas, fitting untuk menghitung mean dan DS hanya dilakukan pada training set (lalu dilakukan transformasi (fit_transform)). Gunakan mean dan DS yang didapat tadi untuk test set (sehingga cukup transform() saja).
MinMaxScaler menskalakan nilai data ke dalam suatu range. Tidak masalah pada data non-gaussian. Formulanya
$$(x_i - min(x)) / (max(x) - min(x))$$.
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range=(-1, 1))
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Ketika membuat obyek dari kelas ini, ada parameter yang bisa diatur: feature_range dengan nilai tuple dengan format (min, max), misalnya (0, 1). Jika ada data bernilai negatif, bisa menggunakan (-1, 1).
Dua scaler ini lemah terhadap outlier (data dengan nilai ekstrem).
Sedangkan RobustScaler (sklearn.preprocessing.RobustScaler) mirip dengan Min-Max, hanya saja menggunakan range interkuartil. Scaler ini tahan terhadap outlier. Formulanya
$$(x_i - Q_1(x)) / (Q_3(x) - Q_1(x))$$,
dengan $$Q_3$$ adalah kuartil atas, $$Q_1$$ kuartil bawah.
Selain tiga di atas, masih ada normalisasi baris sehingga masing-masing obervasi memiliki panjang = 1, binerisasi nilai (misal berat badan (kg) >= 70 menjadi 1, < 70 menjadi 0), dan beberapa lagi.
Referensi
- Brownlee, Jason. How To Prepare Your Data For Machine Learning in Python with Scikit-Learn
- Lin, Jovian. Feature Scaling
- scikit-learn. Compare the effect of different scalers on data with outliers
- scikit-learn. Preprocessing data
- scikit-learn. User Guide